

随着城市建设的快速发展,城市人口越来越密集,交通需求量也不断上升,道路交通压力逐步增加。在交通压力增加的同时,道路阻塞、安全事故频发等问题严重影响了人们的出行效率和生命安全[1]。由于缺少对行人和非机动车的保护,他们成为了交通事故中的弱者,在参与交通活动时最容易受到伤害。对行人和非机动车的保护成为迫切需要解决的问题。
随着无人机技术的发展,无人机在各行业中的应用成为研究热点[2]。无人机图像的目标检测与追踪技术能很好地帮助人们完成一些操作难度大、具有一定危险性、环境恶劣、空间狭小等情况下的工作,例如侦察敌情、交通疏导、物资投送、桥梁损坏勘测、地理测绘、电力设备巡检等[3]。使用无人机进行机动车道上行人和非机动车检测能有效减少人工成本,实现对行人和非机动车的保护。由于无人机在使用时离地面较高,采集到的场景数据中的目标往往具有尺寸较小、形状复杂、容易受环境影响等特点,这些特点对目标检测模型优化设计提出了挑战。
随着深度学习的飞速发展,使用深度学习解决无人机视角下的目标检测问题成为一种更优的方案。2014年Girshick等[4]首先将深度学习应用到目标检测算法,提出R-CNN算法,标志着目标检测从传统手工特征时代进入到深度学习时代。相比传统学习,通过深度学习可以获得更高的准确率和更快的检测速度。与传统学习相比,深度学习优势明显,国内外研究者纷纷放弃传统学习方向,加入到深度学习与目标检测结合的研究中。随着研究的深入,深度学习与目标检测的结合已经形成一套完整的体系。目前,主流目标检测主要分为两种[5],一种是基于区域提议的两阶段目标检测方法,代表算法有R-CNN、Fast R-CNN[6]、Faster R-CNN[7]、Mask R-CNN[8]等;另一种是基于回归的单阶段目标检测,其放弃了区域提议提取框,在保证检测精度的前提下,大幅度提高了检测速度。2016年Redmon等[9]放弃了两阶段中“区域提议+回归”的检测模式,提出了第一个单阶段目标检测器YOLO,开启了经典的YOLO系列目标检测算法。2017年,Redmon等[10]提出YOLOv2,丰富了单阶段家族,其使用Darknet-19作为骨干网络,将批量归一化层加入到每一个卷积层,从而使网络中各层的输入数据分布相对稳定,并使用k-means对数据集进行聚类获得合适大小的锚框,其具有更高的精度和速度。2018年Redmon等[11]对现有的一些经典结构进行整合提出YOLOv3,引入了残差网络模块,使用Darknet53作为主干网络替代Darknet19,去掉了池化层和全连接层,进一步加深网络层数。使用与FPN相似的特征融合策略,在高、中、低3个尺度上检测目标,能够更好地应对尺度差异较大的目标。2020年,Bochkovskiy等[12] 提出的YOLOv4,使用Mosaic进行数据增强、CSPDarknet53作为主干网络、并使用Dropblock随机减少神经元数量,还使用SPP模块和FPN+PANet结构,充分利用语义信息和位置信息进行多尺度特征融合。同年6月YOLOv5出现,其根据参数量分为n、s、m、l、x 5种类型,这5种模型的网络结构一致,通过控制通道数和宽度来决定模型的参数量。随着通道数和宽度的增加,检测精度得到提高,但检测时间和消耗的资源也大幅提升。YOLOv5s是YOLOv5的小型版本,在保证精度的前提下训练速度较快,适合在CPU上进行推断。
本文在YOLOv5s的基础上,提出YOLOv5s-P2S算法,检测机动车道的车辆和行人。
1 YOLOv5检测算法
2020年,Glenn Jocher等研发YOLOv5,其为YOLO系列的第五代,具有很强的目标检测性能。至2022年,YOLOv5已经更新到了第7个版本,与原版相比有了较大变化。在7.0版本中,YOLOv5根据参数量分为了n、s、m、l、x 5种类型,这5种模型的网络结构一致,通过控制通道数和宽度来决定模型的参数量。其架构分为Input、Backbone、Neck、Head 4个部分。
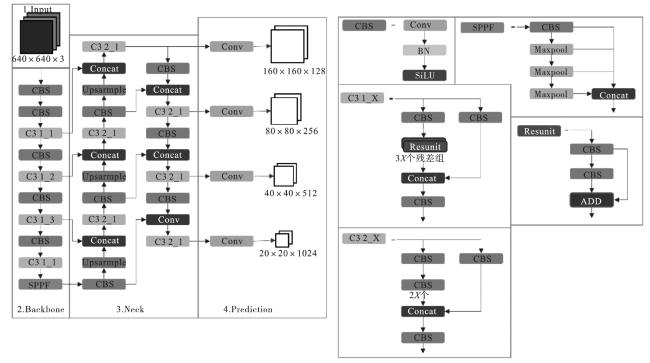
Input:图像输入端,这部分进行图像预处理,将图像缩放至合适大小进行输入,利用Mosaic图像提高算法适应性。
Backbone:特征提取阶段,包含Conv、C3、SPPF等基本结构。Conv用来进行下采样,减小图像尺寸,增加通道数;C3进行特征提取、融合,丰富语义信息;SPPF进行多尺度特征融合。在Backbone阶段C3和SPPF负责特征融合,输入和输出图像尺寸和通道数不变。在7.0版本中用Conv替代了Focus 层,两者作用相同,前者具备更高的适配性和更快的训练速度。同时还用C3替换CSP,简化算法结构,用SPPF替换SPP,减少参数量,提高训练速度。
Head:图像输出端,包含损失函数、预测边界框和非极大值抑制(non-maximum suppression,NMS)3个部分。在7.0版本中,YOLOv5算法搭载了GIOU、DIOU和CIOU损失函数。
2 改进的YOLOv5s-P2S检测算法
无人机航拍图像场景复杂、目标密集且尺寸较小,直接用YOLOv5s算法进行检测会出现误检、漏检等问题,导致检测精度大幅下降,所以需要对YOLOv5s算法进行结构优化和调整。为了使算法更适合无人机视角下的目标检测,在YOLOv5s的基础网络结构上,按照原有PAFPN特征融合方案扩展了Neck层,添加小目标检测层,同时更改检测头结构,添加小目标检测头,对扩展小目标检测层的融合特征进行检测。使用SIOU损失函数替换CIOU损失函数,提高目标检测精度和速度。
2.1 小目标检测层
YOLOv5s的检测头包含P3/8、P4/16、P5/32,分别对应输入图像3、4、5次下采样的特征图大小。YOLOv5s默认输入图像像素尺寸为640×640,P3对应检测层为80×80,拥有更多的浅层特征,感受野在三者中最小,检测8×8以上小型目标;P4对应的检测层为40×40,浅层特征和深层特征相对平衡,感受野中等,用来检测大小在16×16以上的目标;P5对应的检测层为20×20,拥有更多的深层特征,感受野最大,用来检测大小在32×32以上的大目标。无人机拍摄图像中的目标尺寸多为小目标,大部分在32×32以下,部分甚至在8×8以下,所以本文提出P2检测层,对应检测层尺寸为160×160,用于检测更小的目标,拥有比P3更多的浅层特征,能检测大小在4×4以上的目标,有效增强了小目标的检测能力,同时添加小目标检测头。改进后的YOLOv5s-P2S结构如图1 所示。
2.2 改进损失函数
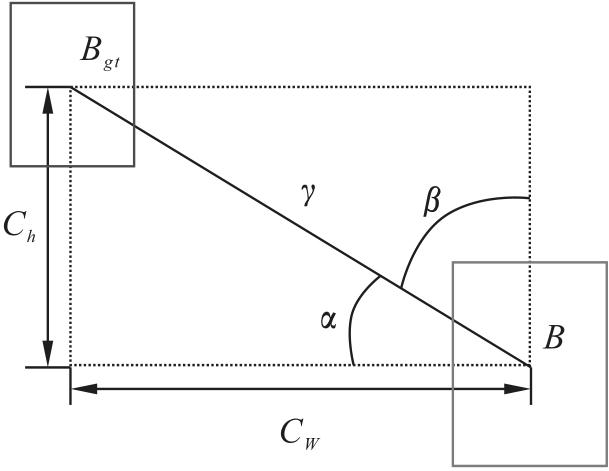
SIOU损失函数有4个组成部分,分别是IOU损失、距离损失、角度损失和形状损失。SIOU的计算如式(1 )、(2 )所示
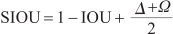
式中:IOU为真实框与预测框之间的交并比;Bgt 为真实框;B为预测框;Δ为距离损失;Ω为形状损失,计算过程如式(3 )、(4 )所示
SIOU应用的角度损失有效提高了模型的精度,促进了模型的收敛,使小目标的检测能力得到进一步提高。
3 实验设计
3.1 数据集与实验环境
VisDrone2019数据集由天津大学机器学习和数据挖掘实验室AISKYEYE团队收集。基准数据集包括288个视频片段,由261 908帧和10 209幅静态图像组成,由各种无人机摄像头捕获,具有覆盖范围广泛,地理位置丰富、环境复杂、物体和密度多样等特点。其中包含行人、驾驶人员、自行车、轿车、火车、卡车、三轮车、遮阳棚三轮车、公交车和摩托车共10个类别。因此,本文针对无人机视角下车辆与行人的特点进行优化,把VisDrone2019数据集的7 019张图片作为训练集,1 580张图片作为测试集。
算法训练相关环境配置参数如表1 所示。
表 1 环境配置参数 |
| 软硬件 | 版本或型号 |
|---|---|
| 操作系统 | Windows11 |
| CPU | i5-13400f |
| GPU | NVIDIA RTX 3050 |
| Python | 3.11 |
| Pytorch | 2.1.0 |
| 训练软件 | Pycharm2023 |
| CUDA | 12.1 |
3.2 实验评价指标
为了评估算法的检测性能,本文采用3个目标检测领域常用指标进行检测,分别是参数量Params、计算量GFLOPs和平均精度mAP50。Params为模型包含的整体参数量,单位为M(million),用来计算计算机的内存消耗。GFLOPs是浮点运算次数,即计算机每秒进行单位乘以10亿次的浮点运算,用于判断模型训练消耗的计算量。采用mAP50(IOU阈值为0.5下各个类别平均检测精度)评价模型的检测精度。AP表示在不同召回率下精确率的平均值,其计算与精度P(precision)和召回率R(recall)相关,计算过程如式(6 )~(9 )所示
式中:TP(true positive)为真正例的数量;FP(false positive)为假正例的数量;FN(false negative)为假反例的数量。
4 结果分析
4.1 改进措施的消融与对比实验
对比不同检测层的使用对模型精度的影响,实验验证结果如表2 所示。
表2 检测层消融实验 |
| 检测层 | mAP50 | Params/M | GFLOPs |
|---|---|---|---|
| P3+P4+P5 | 0.371 | 7.04 | 15.8 |
| P2+P3+P4 | 0.405 | 5.44 | 17.9 |
| P2+P3+P4+P5 | 0.416 | 7.24 | 19.3 |
由表2 可知,添加P2检测层后,模型精度提高至0.416,参数量小幅增加。结果表明,小目标检测层在浅层提取的特征具有丰富的小目标特征信息,提高了小目标检测精度,减少了小目标的漏检情况。尝试去除P5检测层后,参数量减少,模型精度下降。为了获得更高的检测精度,本文保留P5层进行后续实验。
为验证不同损失函数对模型和数据集的有效性,将YOLOv5s默认的CIOU和主流的WiseIOU、NWD、MPDIOU进行对比,以YOLOv5s为基准模型进行损失函数对比实验,实验结果如表3 所示。
由表3 可以看出,使用SIOU损失函数的YOLOv5s模型检测精度最高,具有最高的适应性。
为更加直观地体现小目标检测层和SIOU损失函数对YOLOv5s的提升效果 ,本文进行了消融实验。为确保实验环境相同,Batch size设置为16,epoch设置为300,使用YOLOv5预训练权重进行训练,结果如表4 所示。
表4 改进方案消融实验 |
| 模型 | P2 | SIOU | mAP50 | Params/M | GFLOPs |
|---|---|---|---|---|---|
| YOLOv5s | 0.371 | 7.03 | 15.8 | ||
| 改进1 | √ | 0.416 | 7.23 | 19.3 | |
| 改进2 | √ | √ | 0.421 | 7.23 | 19.3 |
由表4 可知,以YOLOv5s为基准算法,改进1表示在基准算法上添加小目标检测层,改进2表示在改进1的基础上使用SIOU替换CIOU。
消融实验结果显示,采用小目标检测层后mAP50值从0.371提升至0.416,检测精度明显提高,模型参数量小幅提高。引入SIOU后,模型精度在改进1的基础上进一步提高。
4.2 对比实验与分析
本文将改进后的模型与基准模型、中等大小的YOLOv5m以及YOLOv7-tiny[20]进行对比,结果如表5 所示。
表5 对比实验 |
| 模型 | mAP50 | Params/M | GFLOPs |
|---|---|---|---|
| YOLOv5s | 0.371 | 7.03 | 15.8 |
| YOLOv5m | 0.39 | 20.89 | 48.0 |
| YOLOv7-tiny | 0.382 | 6.03 | 13.3 |
| 本文 | 0.421 | 7.23 | 19.3 |
由表5 可知,与基准模型YOLOv5s相比,本文模型的mAP50值提高了0.05,参数量仅增加0.2M。YOLOv5m模型是中等规模的YOLOv5模型,其参数量约为YOLOv5s的3倍,本文改进的模型以远低于YOLOv5m的参数量获得了较大的精度。YOLOv7是最先进的目标检测模型之一,本文使用与YOLOv5s相同规格的YOLOv7-tiny进行对比实验,mAP50较YOLOv7-tiny提高0.039,检测精度提升明显。综上,本文模型与其他先进模型相比具有一定优势,有效提高了小目标检测精度。
为了验证在无人机视角下改进后的算法对道路单位的检测效果,在VisDrone2019测试集中选取遮挡、密集场景下的道路图片进行检测。图3 a为待检测的道路车辆行人图片,图3 b为原始YOLOv5s模型的检测结果,图3 c为YOLOv5s-P2S模型的检测结果。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
由图3 b和图3 c对比可以看出,基准模型会对公路上的目标出现漏检现象,没有检测出三轮车。改进后的模型成功检测出三轮车,对道路上的目标没有漏检现象,检测目标的置信度提高。
综上,本文方法通过添加小目标检测层和改进损失函数的方法捕捉到更充分的小目标特征信息。与Yolov5s相比,改进的模型减少了漏检的情况。
5 总结
针对无人机视角下行人和非机动车检测精度低的问题,本文提出了YOLOv5s-P2S目标检测算法模型,通过添加小目标检测层、改进损失函数等方式,提高了YOLOv5s算法模型的检测精度。经实验测试,该算法模型成功检测出漏检的三轮车。在与其他先进深度学习模型的对比中,本文提出的YOLOv5s-P2S模型的检测精度有所提高。在未来的研究中,可以添加针对小目标的注意力机制,以提高小目标的检测精度,使其更适合无人机视角的目标检测。