

1 问题描述与算法设计
1.1 问题描述
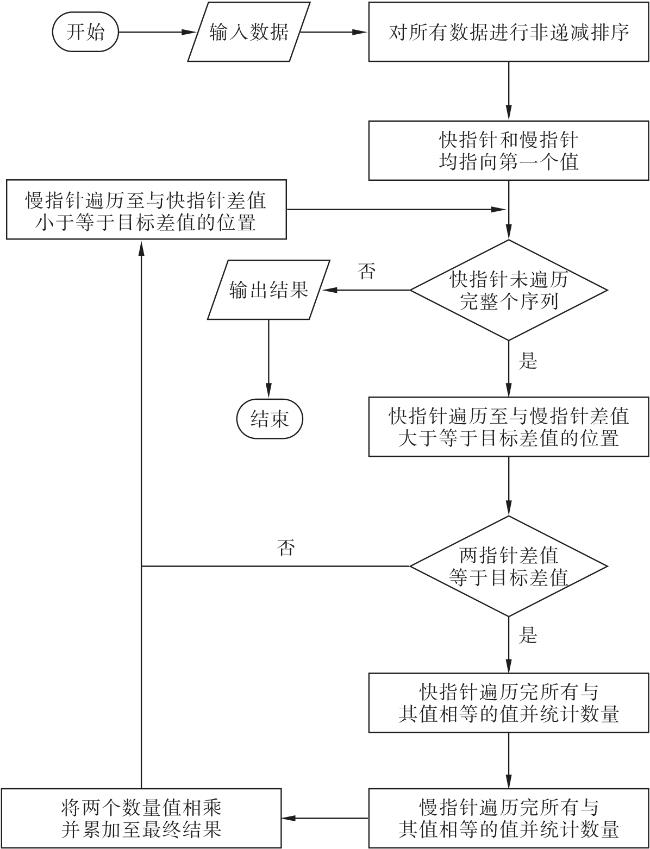
1.2 算法实现流程
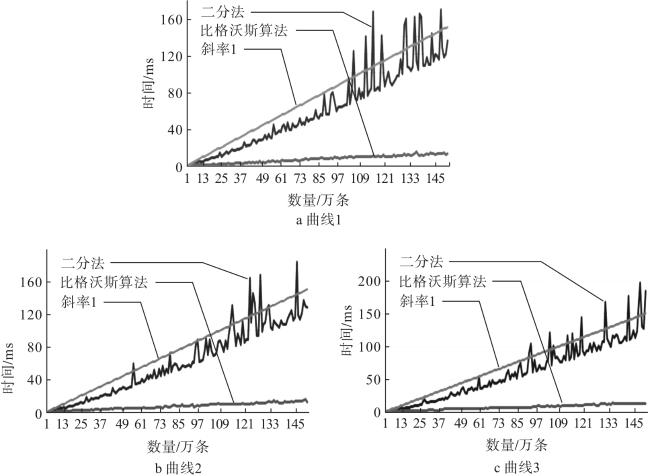
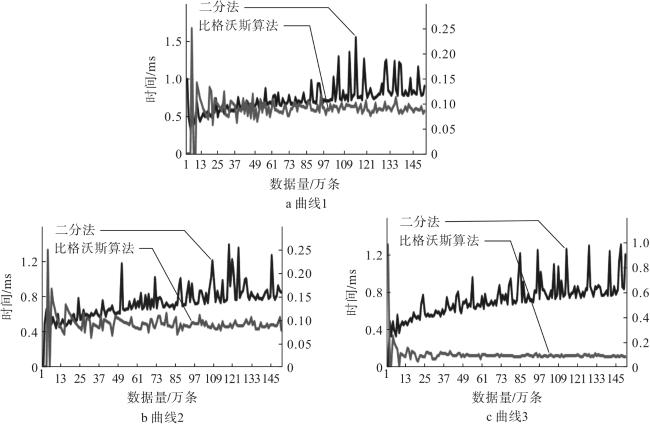
2 算法复杂度分析与对比
2.1 算法对比
表1 算法对比 |
| 算法名称 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 双指针算法 | ||
| 二分法 | ||
| 哈希 |
2.2 二分查找算法
| 算法 二分查找算法BinarySearch(arr,target) |
|---|
| input: arr为排序好的所有数据target为目标值 output: 目标值target的数量 1 left<-0 2 right<-length(arr)-1 3 count<-0 4 while left<=right 5 do 6 mid<-(left+right)/2 7 if arr[mid]=target 8 do 9 count<-count+1 10 break 11 else if arr[mid]<target 12 do 13 left<-mid+1 14 else 15 do 16 right<-mid-1 17 end if 18 end while 19 return count |
2.3 哈希查找算法
| 算法 哈希查找算法Hash(A,n,C) |
|---|
| input: A为所有数据n为数据总量C为目标差值 output: 差值为C的对数 1 ans<-0 2 hashTable<-空的哈希表 3 for i from 0 to n-1 4 do 5 diff<-A[i]-C//计算目标差值 6 if hashTable.contains(diff) 7 do 8 ans<-ans+hashTable.get(diff)//将该差 值出现的次数累加到结果中 9 end if 10 if hashTable.contains(A[i]) 11 do 12 hashTable.set(A[i],hashTable. get(A[i])+1)//将当前元素的出现次数加1 13 else 14 hashTable.set(A[i],1)//将当前元素的 出现次数设为1 15 end if 16 end for 17 return ans |
2.4 双指针算法时间复杂度
2.5 双指针算法空间复杂度
| 算法 双指针算法Bigglesworth(A[],n,C) |
|---|
| input: A为排序好的所有数据n为数据总量C为目标差值 output: 差值为C的对数 1 ans<-0,i<-0,j<-0 2 while i<n 3 do 4 while i<n and A[i]-A[j]<C 5 do 6 i<-i+1 7 end while 8 if A[i]-A[j]=c 9 do 10 cnt_i<-1,cnt_j<-1 11 while i<n and A[i<-i+1]=A[i-1] 12 do 13 cnt_i<-cnt_i+1 14 end while 15 while j <n and A[j<-j+1]=A[j-1] 16 do 17 cnt_j<-cnt_j+1 18 end while 19 ans<-cnt_i*cnt_j 20 end if 21 while j<n and A[i]-A[j]>C 22 do 23 j<-j+1 24 end while 25 end while 26 return ans |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}