

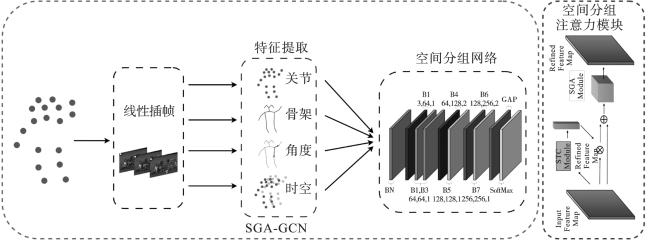
无人机具有极强的灵活性和远程跟踪能力,在空中搜索救援、巡逻监视等领域发挥着重要作用。人体行为识别(HAR)是实现其自动化的关键技术和重要环节,也是计算机视觉和人工智能领域的研究热点[1-3]。和常规的HAR类似,无人机HAR可以依赖不同的数据模态,例如RGB、光流和骨骼数据。与其他模态数据相比,骨骼数据具有实时性、鲁棒性强、数据量小但信息量大等优势。因此,本文专注于研究基于无人机视频骨骼数据的HAR。
近年无人机HAR[4-6]的研究热度有所提升。为捕捉样本的更多运动信息,Hu等[7]提出了FR-AGCN,通过增加逆向数据,使得一些动作具有更好的区分度。Xie等[8]提出TE-GCN,引入因果卷积,使模型能专注于重要的时间步长。Cheng等[9]提出MSST模块捕捉时空特征,构建多尺度特征聚合的轻量级动作识别模型。Huang等[10]提出MS&TA-HGCN_FC增加空间和时间的注意力机制,并使用全连接图卷积提高不同动作骨架间的差异性。
虽然现有的深度学习模型在无人机HAR上已经取得了一些成果,然而,随着模型研究的不断加深和扩展,网络的复杂度也随之增加,导致模型参数量的爆发式增长,因此训练与执行时间极大增加,从而无法有效地应用到实际场景中。在不损失性能的前提下,降低网络复杂度成为目前研究中的关键问题。本文提出空间分组注意力(spatial grouping attention,SGA),在降低网络深度、减少参数量、缩短训练和执行时间情况下依旧保持良好的性能。分析可知,局部肢体特征能精准地反映行为,为了降低无益于区分行为的局部特征对模型的干扰,本文将人体划分成多个区域,利用局部和全局特征的相似性,捕获能够代表全局运动的肢体部位,采用注意力机制在特征图中提升对关键部位的表示能力,使模型关注于更能区分行为的局部特征;其次,由于部分不同行为仅具有细微差别,导致帧中的关节坐标相似,从而模型容易被具有相似运动轨迹的行为干扰。为了缓解这一问题,本文捕获身体部位之间的相对运动,提出骨骼角度的高阶特征编码(higher-order feature coding of bone angles,HFBA)方法,捕捉更能反映细微运动差异的肢体关节间角度的变化,降低模型被相似行为的干扰;最后,针对低帧率问题,现有大多方案采用重复采样或填充空帧的策略,这些方法都未增加样本信息。因此,本文采用基于帧间差异的线性插帧(linear interpolation,LI)方案进行帧间插值,增加了样本信息量。
1 相关工作
目前,利用图卷积网络(graph convolutional network,GCN)进行骨骼数据的HAR已成为主流。基于GCN的方法是将人体骨架简化为一个由顶点和边组成的图,其能自然地对人体进行建模,从而取得较好的效果。李志新等[11]通过小波包变换获取原始信号的时频特征,并在结构特征中加入距离约束,更好地处理时间序列信息。Li等[12]建议使用行为连接来表示任何顶点之间的潜在关系,并使用结构连接来表示高阶特征。Shi等[13]提出基于自适应图卷积网络(attentive graph convolutional networks,AGCN)的两流结构2s-AGCN(包括关节流和骨架流)。AGCN在表示人体物理结构的原始邻接矩阵的基础上,参数化了两类邻接矩阵,增加了模型对图结构的灵活性。Shi等[4]在AGCN基础上提出空间通道注意力(spatial-temporal channel attention,STC)模块,利用串联的空间、时间和通道注意力有效提升了模型性能。Song等[14]提出基于多输入分支策略的模型,该模型通过先验知识将原始骨骼数据分为3类,进行早期融合后作为网络的输入。Cheng等[15]提出一个轻量级的GCN模型Shift-GCN,其使用移位卷积操作替代了二维卷积操作,用更少的参数量和计算量达到更好的模型性能。
为了在行动完成之前预测行动标签,Li等[16]在HARD-Net中提议重点关注早期的HAR。Yin等[17]提出SPIANet来模拟人体运动过程中关节之间的复杂时空纠缠,通过平行聚合人体不同部位的特征,解决大多数动作仅与局部关节的动态特征相关的问题。She等[18]提出具有EM动态路由的图卷积网络EMD-GCN,将多个关节点有效地聚类到相应的图拓扑中,使得模型能够学习到不同的结构特征。李梦荷等[19]提出将骨骼点提取与动作识别相结合的方法,利用OpenPose算法提取关键点数据,并通过帧窗口矩阵的特征描述方法完成多人行为识别。宋震等[20]提出根据人体关节点及连接关系的拓扑结构将全局空间特征划分为人体局部空间特征,学习各关节内部的特征关系,并通过融合各部分特征向量,学习关节间的协同关系。李炫烨等[21]提出多注意力时空图卷积网络,根据时间序列和骨骼自然连接构建连通图,利用具有多注意力机制的时空图卷积网络自主地学习空间和时间特征。
虽然现有工作推进了图卷积网络用于行为识别的发展,但大多工作需要较高的算力和较多的推理时间成本。另外,现有方法在区分具有相似运动轨迹的行为时表现不佳,这为模型应用于实际场景带来了一定的挑战。
2 空间分组注意力图卷积网络
2.1 骨架图定义
定义骨架图为 , 和 分别表示人体骨骼中的关节点和骨骼。 是人体的 个关节点, 是由邻接矩阵 定义的边集, 。如果在骨架图中关节沿 指向 ,则 否则 ,其中 。
在网络中,每个输入行为样本的特征张量为 ,输出为 ,其中: 是通道数; 是帧数; 是关节数。GCN网络在时间 处 层与 层更新规则为
式中: ,是具有增加自循环来保持自身特征的骨架图; 是 的对角矩阵; 是激活函数; 为需要学习的权重。
2.2 空间分组注意力模块
在实际应用中,如何在保持良好识别性能的同时降低模型复杂度是目前研究的热点。本文通过降低网络深度来减少模型参数量,降低模型训练时间,提升模型执行效率。同时为保持模型性能,提出空间分组图卷积网络。分析可知,由肢体构建的局部特征能有效反映全局行为。因此,利用局部特征与全局特征相似性,捕捉突出行为的关键局部特征,增强注意力图,提升模型的表征能力。
为了提升模型对数据的学习能力,通过突出凸显行为的局部特征来增强特征分布。这种方法可以使模型更好地捕捉数据中的关键信息,并提高其性能和泛化能力。本文假设,分出的每个组在同一类别学习过程中都能够从局部信息中捕获同一局部特征。具体方法如下:首先将特征分组,利用整个组的空间整体信息来增强局部区域中特征的学习,防止局部特征中相似噪音特征对特征图推断的影响,并通过空间平均函数计算全局特征来近似表示该组学习到的运动特征,如式(2) 所示。
式中: ; ,其中 为划分的局部数; 。
然后,利用全局特征为每个特征生成相应的重要性系数,其在一定程度上度量了全局特征和局部特征之间的相似性,因此对于每个局部区域有
不同样本在同一组上的注意力掩码分布会存在差异,需要归一化到一定范围,因此对特征输入进行映射有
式中: ; 和 为 的均值和方差; 为实参数; 和 为可学习的参数。
2.3 骨骼角度的高阶特征编码
解决如戴眼镜与带耳机等具有相似运动轨迹的行为时,即使执行不同行为,但帧中关节坐标仅具有微小差异,模型被这类行为所干扰。本文提出骨骼角度的高阶特征编码方法,有效地捕捉关节和身体部位之间的关系,通过肢体间角度的变化,降低模型受到仅具有细微差别行为的干扰。
现有方法大多使用关节和骨架特征形成双流结构。本文提出骨骼角度的高阶特征编码方法,将高阶角度特征作为新的特征提取方式,使得模型能够捕获更多运动信息。高阶角度特征的提取具体可表示为
式中: 分别为骨架图中的3个关节点; 表示以节点 为顶点的角度。定义 为目标关节, 的坐标分别表示为 。则由 指向 和 的向量可表示为
式中: 和 分别为由 指向 和 的向量。
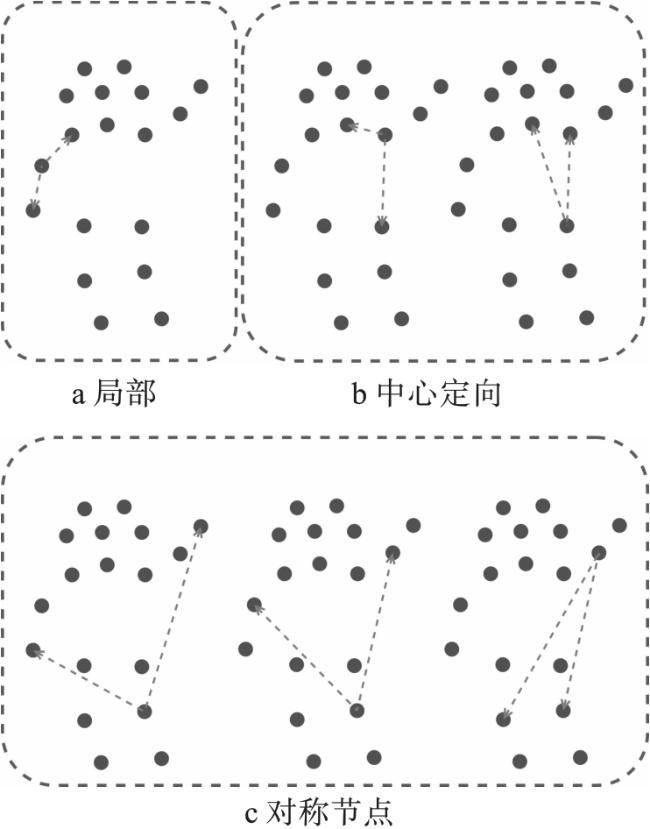
然而,由于各关节间的组合方式较多,实际运用时角度特征的数量不宜过多,因此提出局部角度、中心定向角度和基于成对关节点的角度定义。
(1) 相邻节点角度定义如图2a所示。如果目标节点恰好具有2个相邻节点时,利用式(5) 计算角度特征;如果仅有1个相邻节点时,则将角度记为0;如果目标节点具有2个以上相邻节点时,如肩部,其与颈部、肘部相连接,与髋部相比,肘部和颈部更加灵活,运动范围更广,对捕获行为的运动特征更加有益。因此选取肘部或者颈部节点,如果骨架图中无颈部节点,则可以用相近的头部节点替代,例如鼻子节点等。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
(2) 中心定向角度定义如图2b所示。对于构建目标关节与颈部、髋部之间的角度特征,使用颈部-目标关节-髋部,以及颈部-髋部-目标关节两个角度测定。若目标关节为颈部或者髋部,则将角度特征记为0。
(3) 对称节点的角度定义如图2c所示。可用式(5) 计算目标关节与对称关节点之间的高阶角度特征,对称关节包括手部、肘部、肩部、膝部及脚部。这5个对称关节点之间的交互构建了复杂多变的高阶角度特征,极大地增益了模型对于人体行为的识别。
2.4 插帧策略
无人机拍摄视频会有低帧率问题,因此需要增加样本信息量。由于不同行为所需的时间存在差异,相同行为在不同场景、设备、环境和人物下所需的时间也会有所不同,因此各个样本的视频帧数也存在差异。为解决上述2个问题,本文采用基于帧间差异的线性插帧方法。
表1 线性插帧算法表 |
| 步骤 | 插帧算法 |
|---|---|
| Step 1 | , |
| Step 2 | |
| Step 3 | |
| Step 4 |
为对原视频第 帧提取的骨骼数据; 为骨架数据第 帧和 帧之间的空间位移矩阵; 是骨骼数据中第 帧和 帧之间插入帧的单步移位矩阵。
为解决 不为正整数的情况,有如式(7) 所示办法。
将 更新有 。
3 实验结果与分析
本文在UAV-Human数据集上对最终模型进行了评估,并与其他基于骨架的HAR任务方法进行比较以验证模型的性能。
3.1 数据集
Li等[23]提出UAV-Human数据集。由一架无人机在多场景下采集,包含67 428个多模态视频序列和119个人物。基于骨架的行为识别包含155个行为类别,并且作者定义了两种跨主题评估标准用于HAR(CSV1和CSV2),每个评估标准使用89个人物的行为样本进行训练和30个人物的行为样本进行测试。对于不同的跨主体评估标准的区别是用于训练和测试主体的ID不同。本文遵循这些协议并计算top-1和top-5准确性。
3.2 实验配置
所有实验都是在Pytorch深度学习框架上进行。本文应用Nesterov动量的随机梯度下降算法,为优化策略将Nesterov动量、权衰减和初始学习速率分别设置为0.9、0.000 1、0.1,并在第30和第40个epoch除以10,训练过程在第60个epoch结束。所有实验都是在一台配有Xeon(R)Gold 5218R CPU(2.1 GHz)、RTX 4090GPU*1和128GB RAM的计算机上进行的。
3.3 实验方法与结果
本文将骨骼数据进行高斯中心增强,补充样本关键信息后仍使用UAV-Human中的原始数据预处理策略。先将骨骼数据填充空帧以使其在帧数上均匀。随后对每个样本进行归一化以统一每个通道的数据分布。
在SGA-GCN中,数据分支输入分为关节、骨架、角度和时空特征。为了便于描述,本文根据输入数据定义了网络输入。具体地,FJ、FB、FA、FM作为输入到网络的4个数据流分支。此外,FJB表示FJ和FB最终融合结果。FBM、FBR等可以类比推导,SGA-GCN是由AAGCN模型进行改进,因此本文将在多角度与AAGCN模型比较。
3.3.1 参数量、训练及推理时长分析
表2 SGA-GCN模型与AAGCN的参数量比较 |
| 方法 | 参数量( ) |
|---|---|
| AAGCN | 3.78 |
| SGA-GCN | 2.51 |
表3 SGA-GCN模型与AAGCN的单轮训练时长比较 (s) |
| 方法 | 时间 |
|---|---|
| AAGCN | 91 |
| SGA-GCN | 69 |
表4 SGA-GCN模型与AAGCN线的执行时长比较(每100个执行样本) (s) |
| 方法 | 时间 |
|---|---|
| AAGCN | 11 |
| SGA-GCN | 8 |
3.3.2 多分支融合消融实验
表5 在UAV-Human数据集Csv1评估标准上,增加不同分支后的识别性能 (%) |
| 方法 | TOP-1 | TOP-5 |
|---|---|---|
| FJB | 42.90 | 64.06 |
| FJM | 42.71 | 63.52 |
| FJA | 42.65 | 64.12 |
| FBM | 41.35 | 61.74 |
| FBA | 41.05 | 63.09 |
| FMA | 40.48 | 61.82 |
| FJBM | 44.52 | 64.69 |
| FJBA | 44.20 | 64.90 |
| FBMA | 42.84 | 63.36 |
| FJBMA | 45.58 | 65.40 |
表6 在UAV-Human数据集Csv2评估标准上,增加不同分支后的识别性能 (%) |
| 方法 | TOP-1 | TOP-5 |
|---|---|---|
| FJB | 68.38 | 91.10 |
| FJM | 68.30 | 91.17 |
| FJA | 68.25 | 90.89 |
| FBM | 64.54 | 89.30 |
| FBA | 64.63 | 89.63 |
| FMA | 67.19 | 90.18 |
| FJBM | 70.86 | 91.91 |
| FJBA | 69.03 | 91.56 |
| FBMA | 69.03 | 91.50 |
| FJBMA | 71.50 | 92.45 |
从表6可知,增加不同数据分支对模型识别性能的提升是可行的。在UAV-Human数据集上将4个分支结果融合后,与双分支FJ和FB融合结果相比,在CSV1和CSV2上分别有2.68%和3.12%的提升。采取增加不同数据分支使网络从不同的角度获取特征,再将多分支数据的优点相联合的方式是有效的。
3.3.3 线性插帧消融实验
表7 在UAV-Human数据集的CSV1基准上,不同的插帧方式模型TOP-1识别性能 (%) |
| 基准 | FE | RS | LI |
|---|---|---|---|
| CSV1 | 41.74 | 43.98 | 45.58 |
表8 在UAV-Human数据集CSV1基准上,不同插帧方式的不同数据分支TOP-1识别性能 (%) |
| 方式 | FJ | FB | FM | FA |
|---|---|---|---|---|
| FE | 38.6 | 38.8 | 32.2 | 35.3 |
| RS | 40.1 | 38.5 | 32.1 | 36.4 |
| LI | 40.6 | 38.8 | 32.9 | 36.8 |
3.3.4 模型评估
在UAV-Human数据集上,比较了最终模型与现有常用方法,结果如表9所示。
表9 在UAV-Hman两个评估标准上与现有方法TOP-1识别精度和参数量对比 |
| 方法 | CSV1/% | CSV2/% | 参数量(×106) |
|---|---|---|---|
| ST-GCN | 30.25 | 56.14 | 3.10 |
| DGNN | 29.90 | — | 26.24 |
| 2s-AGCN | 34.84 | 66.68 | 6.94 |
| HARD-Net | 36.97 | — | — |
| 4s-Shift-GCN | 37.98 | 67.04 | 2.76 |
| AAGCN | 41.43 | — | 3.78 |
| MS-G3D | 43.94 | — | 6.40 |
| FR-AGCN | 43.98 | 69.50 | 6.94 |
| TE-GCN | 42.50 | 68.20 | 3.10 |
| PB-GCN | 37.48 | — | 2.90 |
| MSTA-GCN | 44.32 | 70.69 | 12.00 |
| 4s-MSSTNET | 43.00 | 70.10 | 3.10 |
| SGA-GCN | 45.58 | 71.50 | 2.51 |
从表9中可知,本文提出方法的识别性能在UAV-Human数据集上优于现有的方法。与早期的ST-GCN方法相比,SGA-GCN在CSV1基准上具有15.33%的提升,与AAGCN相比有4.15%的提升。本文提出的方法与大多数网络的参数量相比都有所减少,与AAGCN相比参数量减少了33.46%,有效降低了网络的复杂程度。总之,SGA-GCN在关节特征、骨架特征、角度特征、时空特征4个数据分支上提取不同数据特征,联合不同数据分支的优点,优化了无人机骨骼数据的HAR任务是有效的。
4 结论
本文提出空间分组图卷积网络,首先,空间分组注意力利用局部和全局信息的相似性推断注意力图,在降低网络复杂度的同时保持识别性能;其次,骨骼角度的高阶特征为模型提供了不同角度的行为特征,缓解具有相似运动轨迹的行为对模型的干扰;此外,线性插帧方案有效增加样本信息量,使得模型能在训练过程中获取更多的关键帧;最后,本文提出的方法在识别性能、参数量、训练时间和执行时间上都优于现有模型。在未来工作中,将考虑如何完成特征的早期融合,进一步降低网络复杂度,提升网络效率,使得模型更具实用价值。