

随着智能手机的普及和自媒体的蓬勃发展,大数据时代下人们对数据分析[1]的需求更加迫切和必要。狭义数据分析是用统计法对数据进行处理、归纳并提炼数据的有用信息,从而为管理决策提供支持。广义数据分析包括狭义数据分析和数据挖掘。利用多元统计方法挖掘隐藏在数据背后的、潜在的信息的过程称为数据挖掘[2]。在数据分析中,最基本的任务是对数据分类,它主要包括监督学习和无监督学习两种。监督分类中的数据具有类标签(即具有答案),并将数据划分为训练集和测试集,通过训练数据建立一个分类器模型,采用测试集对模型进行修正,使用该模型对未知数据的所属类进行预测[3]。模式识别和机器学习[4]的主要内容也是建立监督学习的分类器。然而,在实际中,原始数据是采用各种传感器检测获取的,没有可用的类标签,因此需要采用无监督学习方法。主要的无监督分类是聚类(clustering)[5]或称探索性数据分析。聚类技术是将未标记的数据划分成有限的、离散的数据子集[5],最大的优势是能够发现数据固有的聚类结构,而不要求原始数据提供类标签信息。按照数据点之间的相似性[6],聚类把数据划分成不同的簇或集群(或组),使得同一簇中数据具有最大的相似性,而具有相异性的数据能被明确地分离开来。根据所生成的数据簇特性,聚类可分为层次聚类和分区聚类。层次聚类是用嵌套分区序列对整个数据集进行分类,从每个数据点作为一个单独集群逐步合并,直到所有样本点都属于同一个聚类的过程称为凝聚层次聚类;与之相反,由所有数据点为一个集群逐步划分到每个样本,形成一个单独聚类的过程称为分裂层次聚类。在没有分层结构的情况下,直接将数据点划分为预先指定数量集群的方法,称为分区聚类。在实际中,应用最为广泛的聚类是分区聚类,而其中最著名且经典的方法是K-均值聚类算法[7-8]及其改进版本。
在数据聚类分析中,经典K-均值聚类算法具有易于执行且它的计算效率高的特点,获得了广泛的应用,然而它也有两个主要缺陷[9-10]:一是聚类结果对算法随机所选择的聚类中心非常敏感,即不同的初始选择将影响算法最终所产生的收敛质心;二是在无推理前提下,用户需要指定数据的聚类数量,这对于现实世界中复杂、未知的数据集来说是不可能的。
为解决K-均值聚类算法的问题,很多学者提出了相应的改进方案。针对随机初始化问题,依据变异系数最大值和相关绝对值的最小值,通过选择两个主变量来计算初始聚类中心[11];采用初始种子选择算法以确定数据的初始划分[12];利用鲁棒密度初始化将种子点定位在数据集的密集区域以实现聚类的初始化[13];在算法每次运行中,使用数据的一个属性创建一个初始聚类,并将多次运行的聚类结果组合起来形成初始的划分[14]。在确定聚类数量方面,将最大稳定集与连续Hopfield网络相结合估计聚类数量[15];为提高差分进化自动聚类(automatic clustering using differential evolution,ACDE)的性能,使用U-控制图法,结合ACDE以确定聚类数量[16];基于查找聚类均值有效性的聚类指数,结合核心函数指数及均值性质确定新的聚类中心和聚类数量[17];通过计算基于中心点的偏差比指数(deviation ratio index,DRI)来确定聚类的数量[18];在数据分区之前,利用相似性矩阵的易感性确定最佳的聚类数量[19]。
从以上分析可知,无论是随机初始化,还是确定数据集的聚类数量,对K-均值聚类算法的聚类结果都将产生很大影响。为此,本文提出最远质心选择和最小-最大距离规则对K-均值聚类算法进行改进;通过标准化和主分量分析的预处理实现数据的降维;利用统计经验法则和肘部法初步估计数据集的聚类数量,并采用轮廓分析法评估聚类的质量,最终确定数据集本身所固有的聚类数量。
1 特征缩放与主分量提取
设数据特征数量为p,样本容量为n,将数据表示为矩阵 X ={xik |i=1, 2, …, n; k=1, 2, …, p},其中 X 的每一行是一个样本 x i (i=1, …, n),每一列是一个特征 x k (k=1, …, p)。
在聚类分析中,采用L 2范数即欧几里得(欧氏)距离来测度数据点的远近,如式(1) 所示。
式中: xik 和xjk 分别表示数据样本 x i 和 x j 的第k个特征值。数据不同特征的取值差别可能很大,甚至它们的度量单位也可能不同。为此,要对数据特征进行缩放的预处理。最典型的缩放包括归一化和标准化。归一化使得特征的取值在[0,1]之间,而标准化使得数据特征服从标准的正态分布N(0,1)。数据特征的标准化为
式中: xjk 为样本点 x j 的第k个特征; σ k 为第k个特征列的标准差。
设数据 X 包含K个聚类,某个聚类Ck (k=1,…,K)对应于第j个特征的质心(centroid) m k 为
式中: nk 为聚类Ck 中的样本数量; m k 为 X 中某一特征列的样本均值。
对数据 X,两个特征 x l 和 x k 的协方差为
式中: m l 和 m k 分别为特征 x l 和 x k 的样本均值。在数据标准化条件下,由于样本均值为零,因此数据的统计特性由样本方差及不同特征间的协方差表示,数据 X 对应的p×p维协方差矩阵 Σ ={σlk | l, k=1, 2, …, p},它的主对角元素为各个特征的方差σi 2(i=1, 2, …, p)。对 Σ 进行特征分解可获得特征值λ和对应的特征向量 v (即PCA中的主分量)。协方差矩阵 Σ 的特征向量 v 和特征值 λ 满足关系
式中:特征值是由标量组成的向量 λ =(λ 1, λ 2,…,λp ),它和特征向量 v 的数量是相同的,都是p维。
PCA通过选择代表主分量信息(即方差)所对应的特征向量的子集来实现数据压缩[22]。特征向量包含的信息由其特征值大小决定。因此,可按照特征值从大到小的次序排列其所对应的特征向量,其中某一个特征值λk (k=1, 2, …, p)的方差解释比计算为
根据各特征值对应Rk 值的大小,假设选择前q(q<<p)个特征值对应的特征列向量构成投影矩阵
式中: E 1是Rk 处在最大位置上的特征向量, E 2是Rk 处在第二大位置上的特征向量,依此类推。PCA要求所选取的前q个特征向量必须占据整个方差解释率中的大部分。
将原始数据矩阵 X 乘以投影矩阵 W,就实现了把 X 从p维降低到q维的特征子空间上,如式(8) 所示。
2 K -均值聚类算法的初始化改进
(1) 对于具有K个聚类的数据 X,随机选择K个数据点作为初始聚类质心向量矩阵 m k (k=1, 2,…, K);
(2) 按照距离最邻近原则,将其他数据点分配给邻近的质心,形成K个聚类Ck (k=1, 2, …, K);
(3) 根据当前所划分的数据结构,遵循式(3) 重新计算(即更新)每个聚类中数据的质心;
(4) 重复步骤(2)和(3),直到相邻两次更新的聚类中心不发生变化,或达到指定的最大迭代次数。
对于分区型聚类算法,最常用的误差度量是平方误差和SSE)[10]
式中:||∙||2表示L 2范数。如果数据点 x i 属于聚类Cj,则权重γij =1,否则γij =0,即SSE本质上是聚类内部的SSE。
由K-均值聚类算法的迭代步骤可知,初始聚类中心是随机选择的,这使得一些中心之间可能相距很近,因而在后续的迭代过程中这些聚类会被合并,从而出现了空聚类。
首先计算任意两数据点欧氏距离,并把距离最远的两个点(假设为 x 1和 x 2)作为初始质心,如式(10) 所示。
式中:D( x 1, x 2)为初始两个质心 x 1和 x 2之间距离。显然,该距离是所有数据点对( x i, x j )(i, j=1, 2, …, n)距离中的最大值,即采用最远质心选择原则。然后,以这两个中心为出发点,利用最小-最大距离规则选择下一个(第3个)中心 x 3,如式(11) 所示。
即第3个中心 x 3与前两个中心( x 1, x 2)距离中的最小者为其他数据点 x i (i≠1, 2)与( x 1, x 2)距离中的最大者。同样地,在这3个中心( x 1, x 2, x 3)所组成的3元组的基础上,仍然利用最小-最大距离规则选择下一个(即第4个)聚类中心 x 4,如式(12) 所示。
依此类推,即可选择其余的聚类中心。
采用式(10 )~(12 )对K-均值聚类算法改进,确保了算法的初始质心之间是完全可分离的,即使后续算法的不断迭代也能避免出现空聚类的现象。显然,这种改进解决了K-均值聚类算法对随机初始化敏感的问题。
在改进方案的基础上,继续K-均值聚类算法步骤(2)、(3)、(4),可获得数据的聚类结果。将经过初始化改进后算法仍称为K-均值聚类算法。
3 聚类数量估计与聚类质量评价
经典K-均值聚类算法不能确保收敛到全局最优[22]是由于人为指定的聚类数量与数据的聚类结构不相匹配所致。为此,本文估计聚类数量思路为:首先,在K可能取值范围[K min, K max]内,用每个K值作为参数运行一次K-均值算法,可获得一系列聚类结果;然后,选择这些结果中最优的SSE所对应的K值作为数据的潜在聚类数量。由此就涉及到两个问题:一是需要估计K的可能取值范围,二是构建合理的聚类性能指标对不同K值的聚类质量进行评价。
由于数据 X 的聚类数量K是有限的正整数,尽管具体K值无法事先得知,但可通过数据统计特性估计出其范围。当所有数据点都属于一个聚类时, X 的最小聚类数量为K min=1;而聚类数量最大的情况是每个样本点形成一个单独聚类,即K max=n。然而,实际数据本身的聚类数量一般满足K<<n,因此只要估计出K的可能最大值K max,就可以构造出聚类数量范围[1, K max]。
统计经验法则常用于对服从正态分布的数据结构进行推断,它表明几乎所有(约99.7%)的数据观测值都将落在以均值m为中心的3个标准差σ之内,即3-σ规则。
对于给定p维数据 X,其对应特征的均值 m j 和标准差 σ j (j=1, 2, …, p)一般都是有限值。考虑数据中所有的特征,则最大的聚类数量K max与最小的K min采用经验规则估计为
式中:round()为取整函数。若利用PCA对数据进行压缩,形成只有q(q<<p)维的特征子空间,这时式(13) 和(14)中j的取值范围就变为[1, q]。一般地,式(14) 计算的结果可能为负值,因此在本文中默认K min=1。
K-均值算法的优化目标是最小化SSE。在K的可能取值范围[1, K max]中,由式(9) 可知SSE失真的取值随着K值的变化而变化。当K值逐渐增加时,数据各样本点也逐渐接近于它们被指定的质心,使得SSE值逐渐下降。为此,只要识别出SSE开始快速增长所对应的K值即可得到数据的聚类数量,这就是著名的肘部法。
式中:D( x i, x j )为欧氏距离;ni 为Ci 中样本数量。若 x i 是Ci 中唯一数据点,则ai =0;否则ai 是 x i 到Ci 中其他样本点 x j (j≠i)的平均距离。显然,ai 值是度量同一聚类中数据点的相似程度。
聚类Ci 中样本点 x i 到其他聚类Ck (k≠i)中数据点 x j (设Ck 中数据点数为nk )的平均距离为
基于bik,聚类Ci 的分离性bi [24]为
式中:K为数据聚类数量;bi 是聚类Ci 的数据点 x i 到与它最邻近聚类Ck (k≠i)中所有数据样本点的平均距离。显然,bi 值度量数据点 x i 与其他聚类中数据点的相异程度。
一般地,bi ≥ai。对数据 X 中每个数据点 x i,其对应的轮廓系数[23]为
式中:si 的取值范围为[0,1]。若bi =ai, 则si =0,即两个不同聚类是难以区分的,这意味着聚类质量很差;若bi >>ai,则si ≈1,即不同集群的数据被明确地分离开,这说明聚类的质量高。
为进一步分析聚类的性能,定义数据 X 中所有样本的平均轮廓系数S为
式中:S用于推断聚类质量。S越大,聚类质量越高,体现为不同聚类的轮廓系数具有大致相同的外观尺寸。
4 本文算法流程
在以上内容的基础上,归纳出本文方案所对应算法的流程与伪代码如下:
初始化改进与可视化确定聚类数量的 K-均值算法
输入:数据的维数(特征数量)p,样本容量N
输出:聚类数量K和质心向量 M =[ m 1, m 2,..., m k ]基本流程
1.数据 X 的标准化预处理;2. If p≥8 go to 3, else go to 4;3.对标准化数据执行 PCA 降维的预处理,使数据维数压缩为q维;4.利用经验法则估计聚类数量范围[K min,K max];5.用肘部法在[K min,K max]中搜索最佳 SSE 对应的聚类数量 K;6.采用最远质心选择和最小-最大距离规则改进经典K-均值算法的随机初始化;7.将K值作为输入参数运行改进的K-均值算法获得聚类结果;8.计算聚类的轮廓系数,利用轮廓分析评价聚类质量;9.确定与数据本身相适应最优聚类数量K;10.返回聚类数量K以及对应的质心向量 M。
5 仿真及结果分析
为验证本文方案的性能,利用不同类型的数据集作仿真,所有试验均在Spyder 5上执行。
5.1 聚类性能度量指标
对于聚类结果的评价,除上述的轮廓系数之外,还有一些常用的聚类质量评价指标,例如兰德指标、互信息分数、同质性(完备性)及其V-测度、Fowlkes-Mallows指标、Calinski-Harabasz指标及Davies-Bouldin指标等。
对于只有两个聚类的数据集,兰德指标[25]定义为
式中:a为在真实标签中处于同一簇中的样本对个数;b为真实簇和算法预测簇中处于不同簇的样本对个数;N为样本容量;分母表示数据集中数据对的总数。
如果数据被分成多于两个簇,则需要采用调整的兰德分数[26]
式中:E[∙]表示数学期望。
U和V之间的互信息分数[27]定义为
式中: U和V分别为对N个数据样本分配的标签; P(i)=|Ui |/N和P'(j)=|Vj |/N分别为从U和V中随机挑选的数据点落入聚类Ui 和Vj 的概率。调整互信息和归一化的互信息分别为
式中:mean[∙]是熵的广义均值。AMI和NMI具有更强的鲁棒性[28]。
同质性指标和完备性指标分别为
式中: H(C|K)和H(K|C)分别为给定簇分配的类(class)的条件熵;H(C)为类的熵;H(K)为簇的熵。
V-测度[29]是一种综合考虑同质性和完备性的评估指标,公式为
Fowlkes-Mallows指标[30]定义为成对精度和召回率的几何平均值,公式为
式中: TP为真标签和预测标签中属于相同簇的点对的数量;FP为属于真实标签中的同一簇而不属于预测标签中的点对数量;FN为属于预测标签中的同一簇而不属于真实标签中的点对数量。
以上指标中,RI、ARI、MI、AMI、NMI、HI、CI、VM、FMI的取值均在[0,1]范围内。其指标值越接近1则聚类质量越高,而越接近于0则聚类质量越差。
式中:K为聚类数量;Rij 为
式中: si 和sj 分别为聚类i和聚类j的每个点与它们的聚类质心之间的平均距离,也称为聚类直径;dij 为聚类质心i和j之间的距离。与以上其他指标相反,DB的值越小,聚类结果越好。
Calinski-Harabasz指标[33]也称为方差比标准,如式(31) 所示。
式中: N X 为数据 X 样本容量;K为聚类数量;tr(Bk )为聚类间协方差矩阵的迹;tr(Wk )为集群内协方差矩阵的迹。CHI值不受范围[0,1]的限制。一般地,CHI值越大,聚类结果越好。
5.2 二维随机数据集
在对聚类算法的测试中,经常使用随机数据验证算法性能。为了可视化的目的,这里仅采用二维的随机数据集进行试验分析。
随机产生的二维Blob数据集是由900个样本点形成的6个自然集群。横轴是特征1,纵轴是特征2。两个特征的均值分别为m 1=2.541,m 2=2.367;而标准差为:σ 1=3.874, σ 2=3.239。该数据的散点图如图1所示。
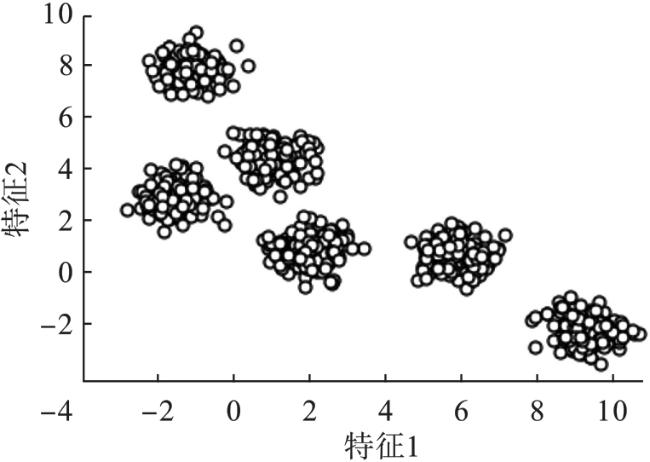
对K-均值算法的主要参数设置如下:指定聚类数量为K=6,最大迭代次数为300。 在实际应用中, 若算法在最大迭代次数到来之前已经收敛,则迭代过程停止。然而,当最大迭代次数到来时, 算法可能仍不收敛,若要增加迭代次数,则计算成本增加。为此,本文附加一个误差容限参数来控制收敛条件。在以下的仿真中,均采用容限值tol=10-4。
K-均值聚类算法对Blob数据集的聚类及对聚类质心的辨识结果如图2所示。
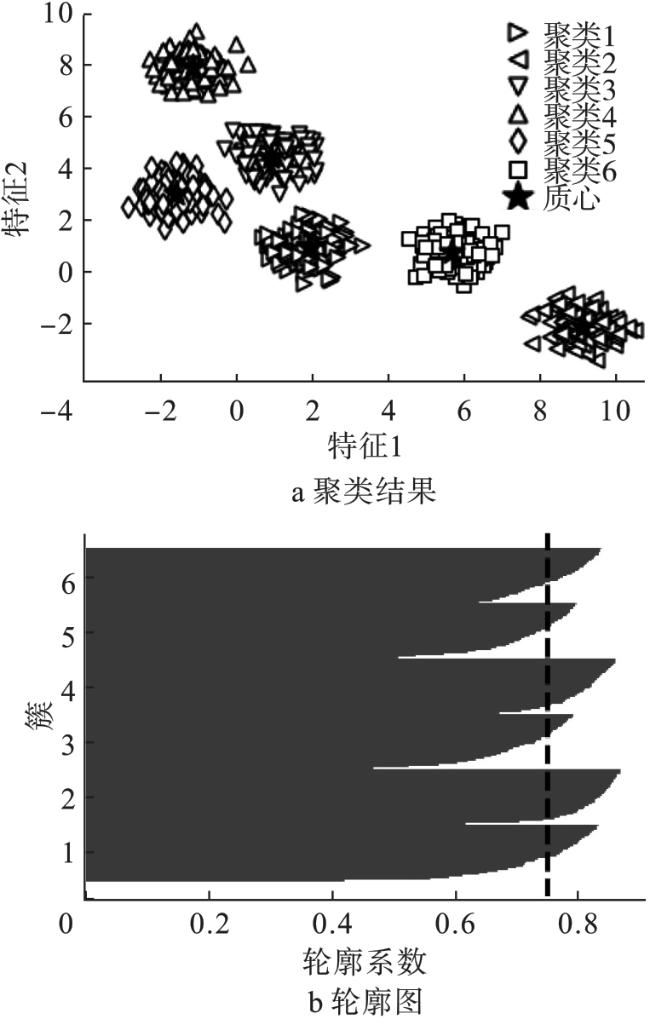
从图2可看出,6个聚类的质心被放置在自然形成数据堆的中心点。这说明,当指定K=6时算法的聚类结果与数据Blob的原始划分是完全一致的。
实际上,数据集 X 固有的聚类数量K一般是未知的,因而需要估计它的范围。将Blob数据集两个特征的均值和标准差分别代入式(13) ,则得到K max=11,即[K min, K max]=[1, 11]。为便于观察,这里仅绘制出变化范围K∈[2, 11]所对应的SSE曲线,其结果如图3所示。
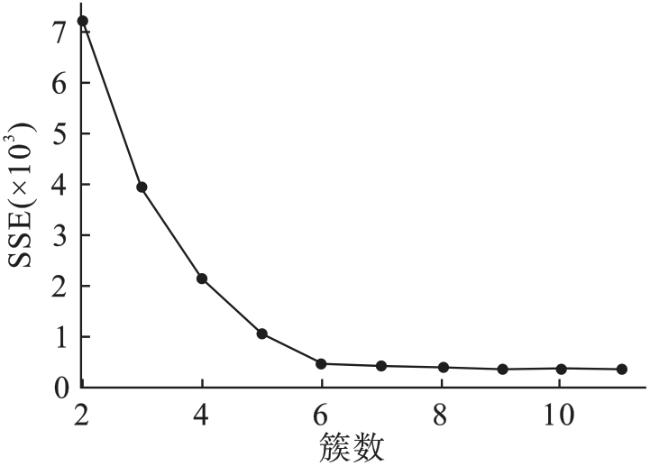
从图3可看出,在K<6时, SSE随K值的变化较剧烈,而当K>6时,SSE随K值变化平缓,即SSE曲线的肘部位于K=6的位置。即数据最优聚类数量为K 0=6,这与Blob数据集是完全吻合的。相反地,若指定的聚类数量K偏离SSE曲线的肘部位置,其结果用如下仿真来说明。
+
若设置参数K=5,则K-均值的聚类结果如图4所示。从图中可知,算法将原本两个集群的数据强制地合并成图中圆线框起来的聚类4。该结果与数据Blob固有的聚类结构相悖。
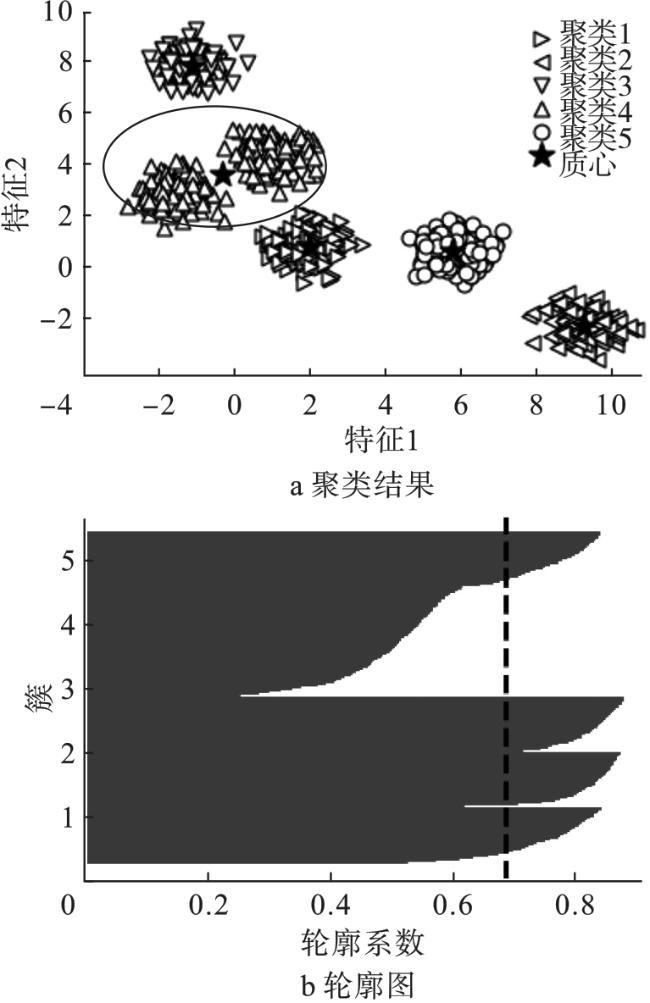
同样地,若设置K=7时,其聚类结果如图5所示。
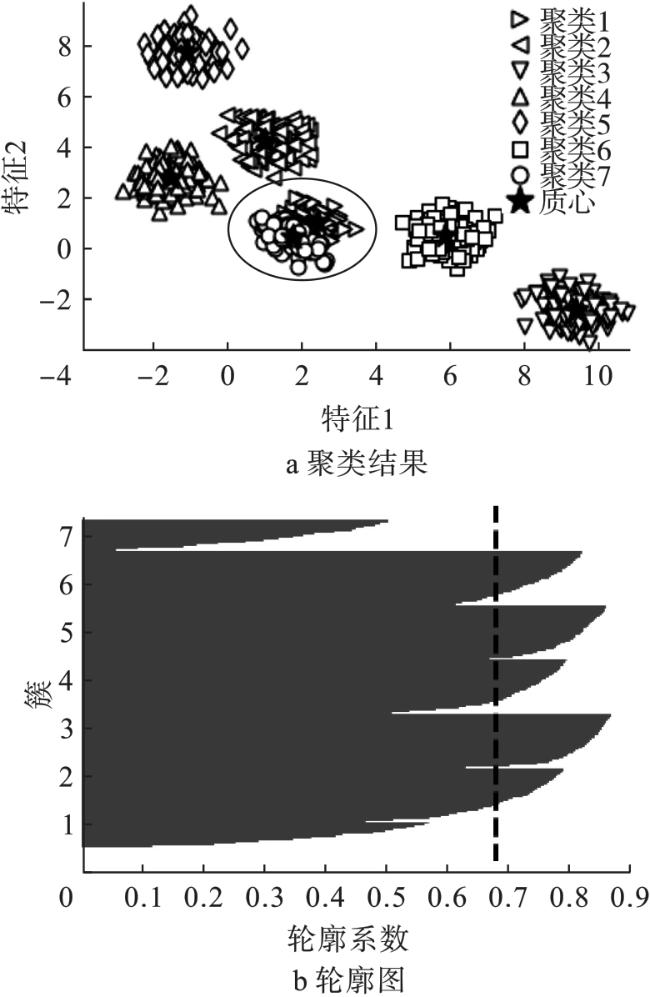
从图5看出,由圆圈框起来的那堆数据被强行地分裂为两个聚类1和7,其对应的质心相距太近,这和数据本身的聚类结构不相符。
将K=5、6、7时K-均值聚类算法对Blob数据产生的聚类性能指标计算出来,如表1所示。
表1 参数 K=5、6、7时Blob数据的聚类性能 |
| K | ARI | AMI | NMI | HI | CI | VM | FMI | DB | CHI |
|---|---|---|---|---|---|---|---|---|---|
| 5 | 0.822 72 | 0.930 62 | 0.931 08 | 0.871 05 | 1.000 0 | 0.931 08 | 0.865 30 | 0.457 98 | 4 652.708 27 |
| 6 | 1.000 0 | 1.000 0 | 1.000 0 | 1.000 0 | 1.000 0 | 1.000 00 | 1.000 00 | 0.347 11 | 9 420.726 63 |
| 7 | 0.949 35 | 0.969 05 | 0.969 33 | 1.000 0 | 0.940 49 | 0.969 33 | 0.958 26 | 0.560 21 | 8 404.354 59 |
从表1可看出,当K=6时,算法的聚类性能明显要比K=5和K=7的性能提高很多。而K=7却比K=5对应的性能高,这是因为聚类数量越多,数据点越接近其被指定的聚类质心。
通过以上对Blob数据集的仿真可知,对于K-均值聚类算法,无论对算法输入参数(聚类数量)K过高或过低,都将会对聚类结果产生影响,造成算法产生的聚类质量恶化。
5.3 高维的实际数据集
美国加州大学欧文分校机器学习数据库包含大量真实数据集,其中的红酒数据集是高维数据。它是对3种不同种类葡萄酒进行化学分析所得出的13种不同成分含量的数据。所谓不同成分就是数据的不同特征,它们分别表示为x 1, x 2, …, x 13。红酒数据集共包含178个样本,3种葡萄酒的样本数分别为59、71、48。为简单起见,将3种葡萄酒的类标签分别表示为1、2、3。对于所有178个样本,计算出它们每个特征的均值m和标准差σ,其结果如表2所示。
表2 红酒数据集13个特征的均值与标准差 |
| x | x 1 | x 2 | x 3 | x 4 | x 4 | x 6 | x 7 | x 8 | x 9 | x 10 | x 11 | x 12 | x 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| m | 13.0 | 2.34 | 2.37 | 19.5 | 99.7 | 2.3 | 2.0 | 0.36 | 1.59 | 5.06 | 0.96 | 2.61 | 746.89 |
| σ | 0.81 | 1.12 | 0.27 | 3.34 | 14.3 | 0.63 | 1.0 | 0.12 | 0.57 | 2.32 | 0.23 | 0.71 | 314.91 |
从表2可以看出,特征x 8和特征x 13的均值相差2 075倍,标准差相差2 624倍,并且各个特征的度量单位也是不相同的。
为便于聚类分析,首先对红酒数据标准化,使其服从正态分布,并计算其协方差矩阵,然后将该矩阵分解为特征值和特征向量。把特征值按降序排列,其结果如表3所示。
表3 降序排列的13个特征值 |
| λ 1 | λ 2 | λ 3 | λ 4 | λ 5 | λ 6 | λ 7 | λ 8 | λ 9 | λ 10 | λ 11 | λ 12 | λ 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4.732 | 2.511 | 1.454 | 0.924 | 0.858 | 0.645 | 0.551 | 0.351 | 0.291 | 0.252 | 0.227 | 0.177 | 0.104 |
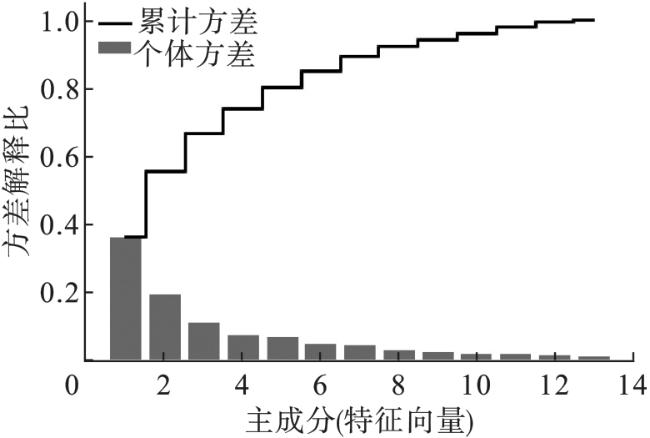
在选择出前两个主分量后,将它们堆叠起来可得到13×2维的投影矩阵 W;其中 W 的第1、第2列即为第1、第2个主分量。对原始的13维数据矩阵 X 进行变换得 X sub= XW。
将压缩后的数据集 X sub在二维子空间上的 散点图绘制出来,如图7所示。
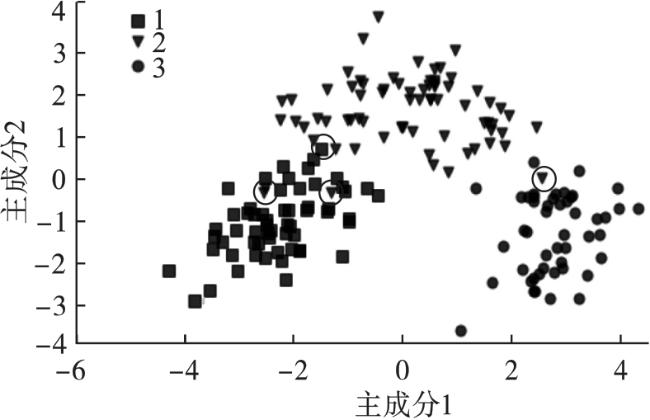
在图7中,用小圆圈标识了3类数据之间互有交叉的样本点。这是由于仅从13个特征中抽取了2个最重要的特征,未能将数据的全部信息利用,因而形成的聚类之间数据点互有渗透。尽管如此, 3个聚类的数据基本上是满足可分离的。
根据所选定的前两个主成分所对应的特征,将前两个特征的均值和标准差分别代入式(13) 中计算可得K max=7,即 X sub的聚类数量范围K∈[1, 7]。在此范围内,绘制出失真SSE随K值变化的曲线如图8所示。
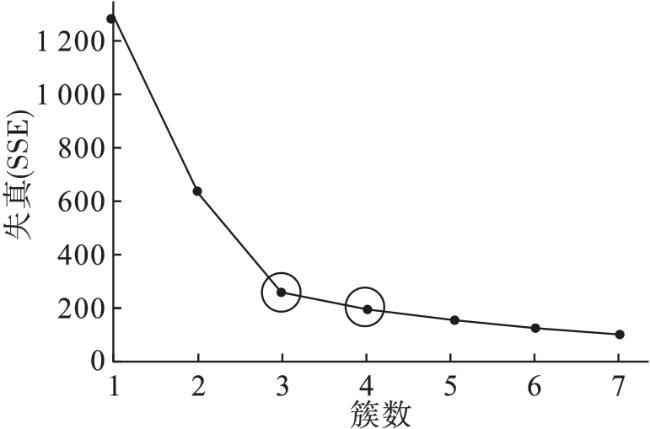
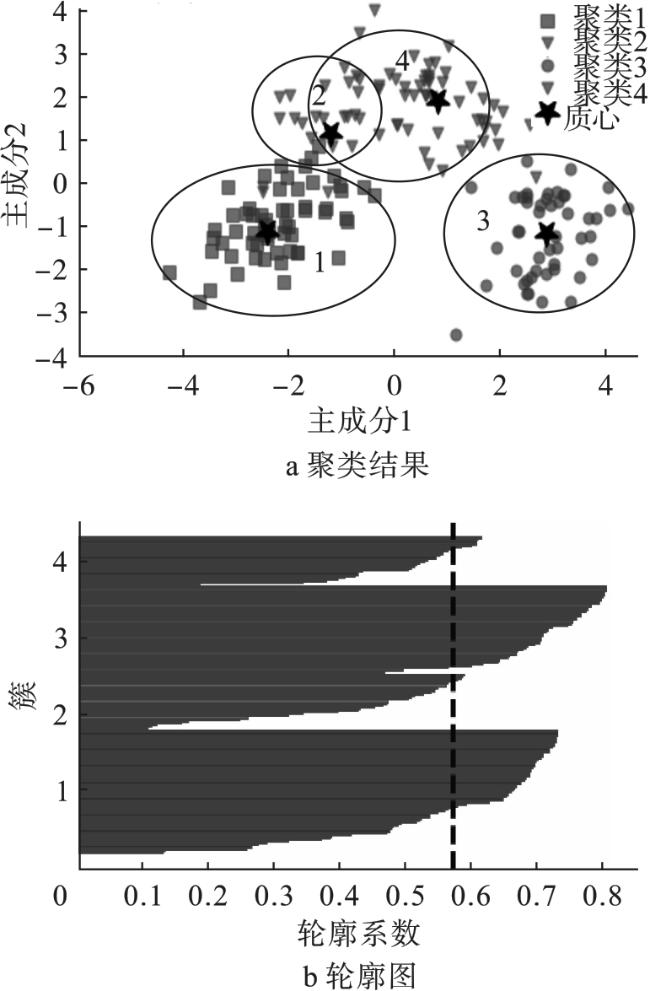
从图8可看出,不能确定失真曲线的肘部是位于K=3还是K=4。为此将K=3、K=4作为K-均值算法的输入参数。
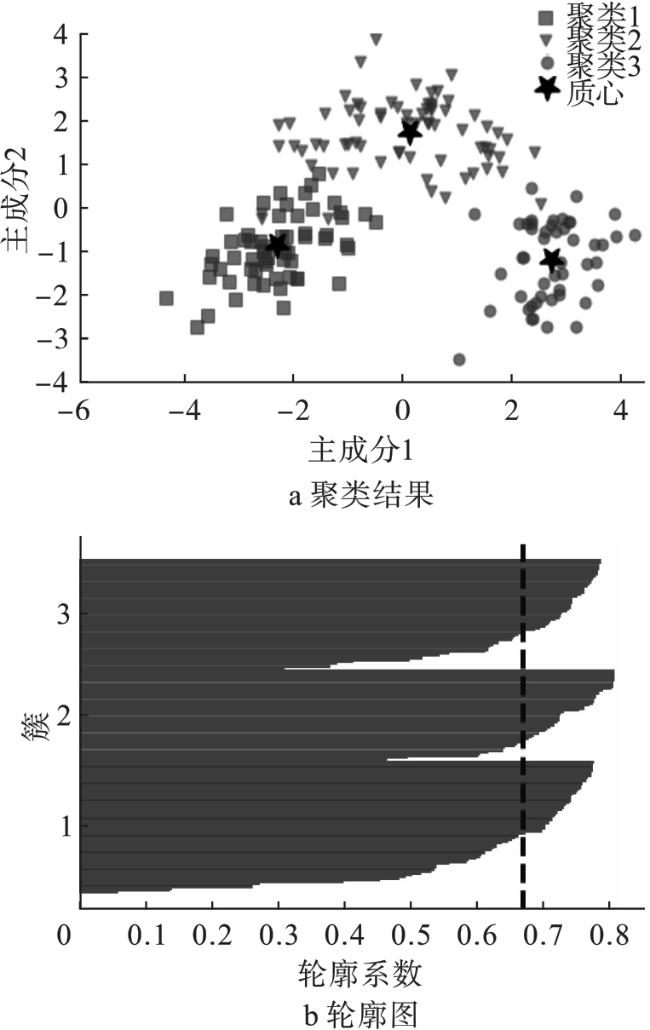
当指定聚类数量为K=4时,聚类结果如图10所示。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
为了更精确地分析K=3和K=4的聚类效果,计算这两种情况下聚类的性能指标,其结果如表4所示。
表4 参数 K=3、4时 X sub 数据集的聚类性能指标 |
| K | ARI | AMI | NMI | HI | CI | VM | FMI | DB | CHI |
|---|---|---|---|---|---|---|---|---|---|
| 3 | 0.895 06 | 0.880 81 | 0.882 07 | 0.883 98 | 0.880 16 | 0.882 07 | 0.930 36 | 0.597 27 | 344.792 59 |
| 4 | 0.677 39 | 0.722 50 | 0.726 39 | 0.822 65 | 0.650 29 | 0.726 39 | 0.778 85 | 0.742 23 | 328.515 50 |
5.4 不同算法效果的比较
为了对比本文方案与其他K-均值改进方法的性能,采用UCI的多个真实数据集进行测试,其选择的数据集的主要信息如表5所示。
表5 UCI数据集的主要信息 |
| 数据集名称 | 维数 | 样本容量 | 聚类数量 |
|---|---|---|---|
| Adult | 14 | 32 561 | 2 |
| Iris | 4 | 150 | 3 |
| Seeds | 7 | 210 | 3 |
| Abalone | 8 | 4 177 | 3 |
| Car Evaluation(Car) | 6 | 1 728 | 4 |
| Dermatology(Derm) | 34 | 366 | 4 |
| Glass | 9 | 214 | 7 |
从表5可知,数据集的聚类数量是已知的。尽管如此,不同的方法仍可能产生不一样的结果,这是由于各种方法依赖于本身的参数设置,且由于对数据中噪声敏感程度不同造成的。为此,以下算法将采用最基本配置进行仿真。
5.4.1 初始聚类质心的选择
为评价不同方法初始质心选择的性能,采用误差百分比和Wilks的α检验统计量。误差百分比[11]计算如式(32) 所示。
式中:ε为数据集中被错误分类的样本数量;N为数据集中样本的总数。
Wilks的α检验统计量[11]如式(33) 所示。
式中: W 为处在平方和与乘积矩阵[11]之内; W + B 为总的平方和与乘积矩阵。α值越小,说明不同聚类间差异越显著。
表6 不同方法的误差百分比 (%) |
5.4.2 聚类数量的确定
6 结论
为解决经典K-均值算法存在的缺陷,本文作了相关研究。其主要贡献体现在以下方面:
(1)对经典K-均值算法采用初始化的改进措施,确保算法不出现空聚类,且具有合理的初始划分;
(2)对高维数据集,利用主分量分析抽取数据集中最重要的少量特征以实现数据压缩;
(3)利用统计经验法则估计数据的可能聚类数量范围,在此基础上,用肘部法搜寻数据集固有的聚类数量;
(4)通过计算不同聚类的轮廓系数,利用轮廓分析法直观地评估算法的聚类质量,从而验证聚类数量选择的正确性。